Refactor or rebuild your custom software?
Custom software maintenance is a spectrum: patching, refactoring, segment rebuilds, or full rebuild. When to do each and why refactoring usually wins.
Most owners are told software maintenance is binary: patch it forever, or rebuild it from scratch. That's the choice sitting in the back of your head when the team starts complaining the tool is slow, or the developer drops a quote for a full rewrite next to a quote for "just keeping the lights on".
It's also wrong. There's a whole middle between patching and rebuilding, and that's where the right answer almost always lives. Refactoring. Segment rebuilds. Staged modernisation. This article is about when each one applies, and why refactoring (the option most owners have never had explained to them) is usually the call.
We wrote the pricing article on what building costs upfront. This is the Urban Lightbulb companion: what it takes to keep the thing alive past year one.
What refactoring actually is
Refactoring is restructuring code without changing what it does. You can think of it like renovating a kitchen: the room stays the room, the stove still cooks, but the layout gets sorted so you can actually work in there.
In software terms that means taking code that's grown messy (functions doing too much, similar logic duplicated in three places, a feature spread across files that don't really belong together) and tidying it. Same behaviour on the outside. Coherent structure on the inside.
It's not a patch, which fixes a bug but leaves the mess. It's not a rebuild, which throws the whole kitchen out. It's the maintenance move engineers reach for constantly on healthy codebases. The 2024 Stack Overflow Developer Survey found technical debt is the top workplace frustration for 62 percent of professional developers. Refactoring is the thing that keeps technical debt from compounding into the rebuild conversation.
The prerequisite nobody mentions: tests
Refactoring has a hidden precondition. You need a test suite.
Michael Feathers' book Working Effectively with Legacy Code opens with a blunt definition: "legacy code is code without tests". The point isn't that tests make code good. It's that without them, you have no way to prove a refactor preserved behaviour. Every change becomes a gamble, and the bigger the change, the bigger the gamble.
Martin Fowler makes the same call in Refactoring: solid tests are the essential precondition. Rename a function, a test tells you whether anything broke. Split a module, the suite confirms the seams still hold. Without that feedback loop, refactoring is guesswork, and guesswork at scale is how bugs ship to production.
If your system has no test coverage, the first refactor is the tests themselves. That's not overhead; it's the mechanism that lets every future refactor happen safely. A developer who pitches a refactor without talking about test coverage hasn't thought hard enough about the actual work.
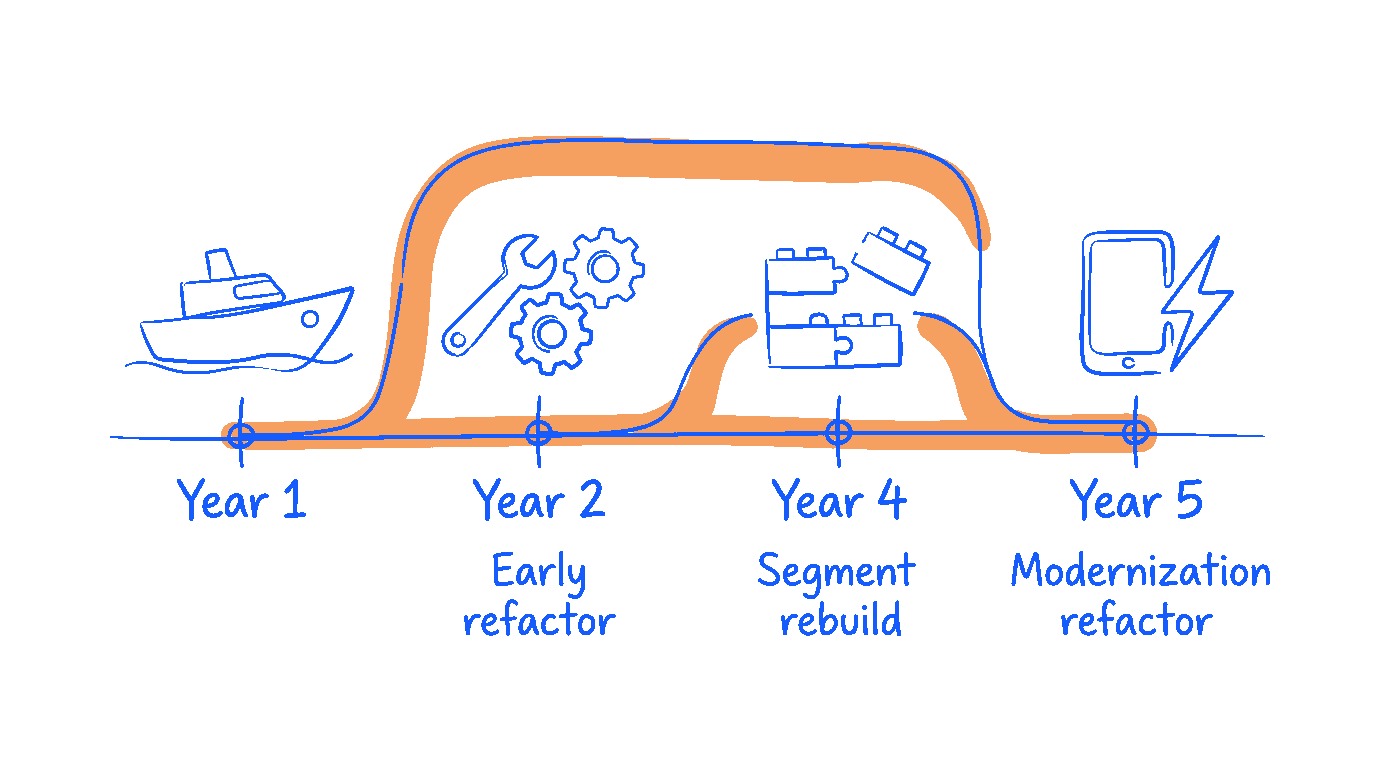
The early refactor, months after launch
Here's a pattern owners rarely hear about, partly because it's a hard one to pay for: the early refactor. A feature ships clean, meets reality for a few months, and the real shape of it becomes visible only in use. Scope creep (users asking for small additions, edge cases appearing, a field turning out to need a relationship it didn't need on day one) pulls the feature sideways. The code that shipped elegantly now has three branches where there should be one, or the same logic in two places, or a model doing a job it wasn't meant to.
That's not a failure of design. It's what scope creep does to any feature. The honest move is to let it stabilise, see the true shape, then consolidate. A week of refactoring a few months in saves months of debt three years later.
In practice this is a hard sell. Most clients don't want to pay to tidy code that "already works", and we understand the reluctance. It happens when the churn has been bad enough that the cost of not doing it becomes obvious, but it's the exception rather than the default. Worth knowing the lever exists, even if you never pull it.
The four-year modernisation refactor
The other refactor worth knowing about happens on a longer horizon. Frameworks move. Laravel ships a major version every year, with 18 months of bug fixes and two years of security fixes on general releases; long-term support (LTS) releases get two and three. Node.js runs its own roughly 30-month cycle. JavaScript tooling reinvents itself every eighteen months whether you want it to or not.
Four years on from a ship date, a system written in best-practice 2022 code is running on a framework that's moved through three or four major releases. Some of that update happens invisibly in dependency patches. Some of it wants a deliberate pass: new patterns, better APIs, features that didn't exist when your system was built.
That's a modernisation refactor. We step back, look at where the framework has gone, and rewrite selected parts of the codebase to match. Not because the old code was wrong. Because the framework now has a cleaner way to do what we were doing manually. Systems we wrote in 2021 have had this treatment in 2024 and 2025, and they're measurably easier to work on as a result.
The bigger claim: most rebuilds should have been refactors
Here's where the industry gets this wrong. Owners are sold ground-up rebuilds far more often than they need them, and it's worth saying why.
Refactoring and segment rebuilds require engineering judgement. They take a team that can read a codebase, decide what's salvageable, and do the careful surgical work of improving it without breaking the parts that work. That's harder than writing greenfield code. Agencies that don't have that capability pitch rebuilds instead.
The cost of that posture is real. McKinsey's research on tech debt found CIOs estimate tech debt at 20 to 40 percent of the value of their entire technology estate, and roughly thirty percent report more than a fifth of their new-product budget getting diverted to cleanup. That's the price of the rebuild-forever cycle playing out across a portfolio: build, accrue debt, rebuild, repeat.
Joel Spolsky made the case against the rewrite reflex back in 2000, calling it "the single worst strategic mistake" a software company can make. He was right then and the maths hasn't changed. Old code embodies years of accumulated bug fixes and edge cases that a rewrite quietly throws out. Most of the time, the smallest change that brings a system back into health is a refactor, not a rebuild.
Segment rebuilds: surgical, not demolition
Sometimes refactoring isn't enough. A single module of the system has aged badly, or was built on assumptions that don't hold anymore. Could be an integration layer, a reporting engine, an authentication piece. The surrounding code is fine. This one piece needs replacing.
That's a segment rebuild: rip out one bounded section, rebuild it cleanly, put it back. The rest of the system keeps running.
The trick is the bounding. Segment rebuilds work when the module has clean seams: clear inputs, clear outputs, a defined contract with the rest of the codebase. If the module's tendrils are spread through twenty other files, it's not a module, it's a tangle, and you can't cleanly swap it. That's when earlier refactoring would have paid off.
When we recommend a segment rebuild, we specify the boundary first. What's in scope, what's out, where the seams are, what the contract looks like before and after. The rebuild then becomes a contained piece of work with a defined cost. Not an open-ended project that keeps eating into the rest of the system.
When a full rebuild is genuinely the call
Ground-up rebuilds are the rarest option. They're justified when the foundation is genuinely gone: the platform is end-of-life with no upgrade path, the core architecture can't support what the business now needs, or a compliance requirement makes the existing model structurally non-compliant.
These cases exist, but they're less common than rebuild proposals suggest. Most of the time, the "foundation is rotten" case dissolves under closer inspection into "a few modules are rotten and the rest is fine", which is a segment-rebuild conversation, not a rewrite.
If a full rebuild is the right call, the signals are specific: the framework hasn't received a security update in eighteen months, the language runtime is past end-of-life, the database is a version nobody supports, or the architecture assumes a single-tenant model and you need multi-tenant. Vibes don't count; named technical facts do.
Two more honest rebuild triggers worth naming. The first is code that's structurally unsalvageable: no separation of concerns, no patterns, the same logic pasted in forty places with slight variations, a codebase with no bones to refactor into. Martin Fowler's signal is the moment you realise refactoring isn't getting anywhere; every cleanup pass just uncovers more of the same mess. At that point the math changes. Salvage cost exceeds rebuild cost. Bad code is bad code, and pretending otherwise costs more than admitting it.
The second is a deliberate tech-stack change. You can't refactor PHP into Node, or jQuery into React. Moving across languages or frameworks replaces the source entirely, which is by definition a rewrite. The question is whether it's worth it. Sometimes yes: a batteries-included framework like Laravel ships with authentication, queues, mail, ORM, and scheduling built in, so the team stops assembling a system from fifteen npm packages and starts shipping features. The productivity delta is real. But the call needs naming. What's the current stack costing you, and what's the new stack buying you, in specific hours and features, not vibes.
Two traps at the edges
Every maintenance decision sits between two failure modes.
Patching too long is the first. Each month you defer a refactor, the debt compounds. The code gets harder to change, new features take longer, onboarding a new developer takes weeks instead of days, and security patches get skipped because the upgrade path is too risky. The cost curve is exponential. By the time it's impossible to ignore, refactoring is no longer an option and you're in rebuild territory you didn't need to be in.
Rebuilding too early is the other. A new framework comes out, a shiny pattern catches someone's attention, a founder gets tired of the old system and decides to start fresh. Greenfield feels good. But you're throwing out years of bug fixes, edge cases, and quiet knowledge that won't come back in the rewrite. Spolsky's 2000 argument still applies: working code has value that's invisible until you try to recreate it.
Both traps come from the same place: not having a clear framework for which maintenance move fits the situation.
How to decide
The honest answer is: get a second opinion from someone who won't profit from the rebuild. A short code audit from an independent team can usually tell you within a week whether you're looking at a refactor, a segment rebuild, or a genuine rewrite situation. It's the question we'd want our own clients to ask before committing to anything, and it's worth paying another studio a few hours to answer it before you commit six figures to a rewrite that might not have been needed.
The portability principle from our article on what to ask a developer applies here too. Code written to be handed over is also code that can be safely refactored.
If your current team says the system can't be refactored, only rebuilt, that's a signal worth investigating. On a recent codebase it might say something about the team. On a ten- or fifteen-year-old system it almost certainly doesn't. Practices in 2014 were different: test suites were thinner, CI was less standard, and the tooling we now take for granted wasn't there. A system built to the standards of its era may genuinely be unrefactorable without the infrastructure a team was never given budget to build. That's often a management story, not a team one. Either way the diagnostic is the same, and the path forward is the same conversation with someone independent.
If you're the one holding the budget
Most development teams know when their code needs a refactor. They feel it every day. What they don't always have is permission to stop shipping features long enough to do it.
If you're in management, that permission is yours to give. Refactoring won't show up in a product demo. It won't land in a release note the sales team can forward. It will quietly make every feature that comes after it faster to build, safer to change, and cheaper to maintain. The teams that ship well over a five-year horizon are the ones whose managers understood this and scheduled the unglamorous work alongside the flashy work.
The healthy balance looks something like: most sprints ship new features, some sprints are explicitly for paying down debt, and the team has a standing permission to flag when a feature area needs a refactor before more is piled on top of it. Not a negotiation every time. A default assumption that maintenance is part of the job.
The teams that never get this permission are the ones you find rebuilding from scratch five years later, because the code got unmaintainable and nobody was allowed to stop long enough to fix it.
The long view
Custom software doesn't have a single dramatic end-of-life moment. It has a series of small maintenance decisions over years, and the health of the system depends on making each one well.
Patch the bugs. Refactor when scope creep has settled and the real shape is clear. Modernise when the framework has moved and the codebase wants updating. Rebuild segments when a piece has genuinely aged out. Keep the whole thing alive past year one, year three, year five. That's what maintenance actually is, and it's what custom software actually needs.